
1. Statistics is divided into two types, descriptive statistics and inferential statistics.
I would recommend that you read up and understand descriptive statistics well, because it forms the basics and foundations as you proceed into inferential statistics. If you have issues understanding descriptive statistics, you might face more problems as you go into inferential statistics. For starters, click on the links above. This post will also revolve mainly around descriptive statistics.
2. Central Limit Theorem (CLT), Normal distribution, and the Bell (-shaped) Curve
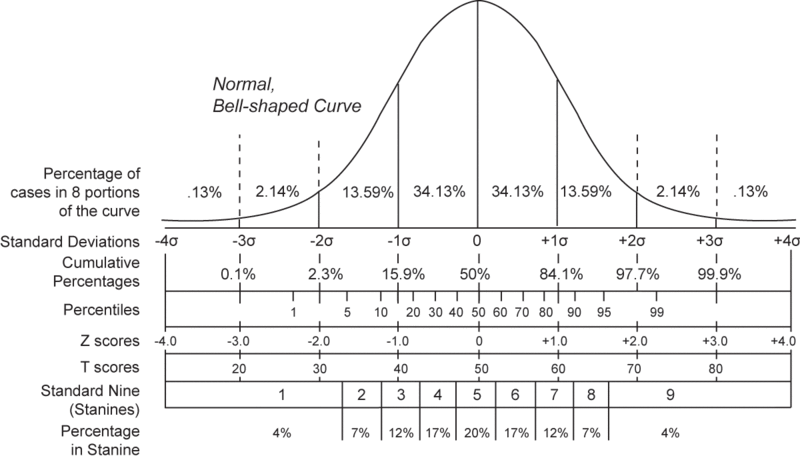
According to the central limit theorem (CLT), the mean of many (or rather 'a lot'; some say at least 30 as a rough minimum) random samples independently drawn from the same distribution is distributed approximately normally. This means that you will get what we call a "normal distribution", also known as the bell (or bell-shaped) curve [as shown above]. In statistics, we often assume that that our means are distributed on a normal distribution; this might not be the case all the time but more often than not, just an assumption. Best way to find out? Use Excel to plot your distribution out and check if it looks like the picture above.
Also to understand the shape of a distribution better and to differentiate one distribution from another, we need to know its central tendency and spread.
3. Population and Sample
This is one of the important things that I would highlight to students. Make sure you know the difference between a population and a sample. A population refers to all members of a defined group that we are studying or collecting information on for data driven decisions. However, it is impossible to to study all the members of a population for a research project, because it just costs too much and takes too much time. Hence, we choose a small group of participants to be representative of the population to undergo the study; this group of participants is the sample. We assume that the sample is representative of the population, and possesses the same characteristics as the population.
Other than understanding the differences between population and sample, you should also know that there are differences between the population parameters and sample statistics. As they are very similar in notation and formulas, students tend to get confused over them.
4. The 3 Ms of Central Tendency: Mean, Median, Mode
Understand the difference between the mean (average), median (middle value or mean of the two middle values or 50th percentile), and mode (value of highest frequency). In reporting of statistics and research articles, you will see the mean more often than the other two. This is because if we assume that the sample is of a normal distribution, the mean is the same as the median and mode, so it would make more sense just to use the mean with standard deviation (its measurement for spread). If the distribution is not normally distributed, report the median or mode rather than the mean.
5. Spread or Variability: Quartiles, IQR, Variance, and Standard Deviation
To understand a distribution or the overall description of a set of data, we also need to know the spread (or variability) other than the central tendency. This can be measured by the above four.
Quartiles tell us about the spread of a data set by breaking the data set into quarters. In a sample of data, the 1st quartile (Q1) is the 25th score, 2nd quartile (Q2) the 50th (also the mean), and the 3rd quartile (Q3) is the 75th score. Quartiles are a useful measure of spread because they are much less affected by outliers or a skewed data set than the equivalent measures of mean and standard deviation. For this reason, quartiles are often reported along with the median as the best choice of measure of spread and central tendency, when dealing with skewed and/or data with outliers. A common way of expressing quartiles is as an interquartile range (IQR). The IQR describes the difference between the third quartile (Q3) and the first quartile (Q1) or Q3 - Q1, telling us about the range of the middle half of the scores in the distribution. You can see an example for quartiles and IQR here.
The standard deviation (SD) is a measure of how spread out numbers are. It is calculated by the square-root of the variance, while the variance is defined as the average of the squared differences from the mean. Hence its formula is "root-mean-square of the differences from the mean"; this is one formula you SHOULD know how to do. In my definition, the SD (or σ) is a averaged measure of how far each of the values deviates from the mean, which also means that you can use the SD to calculate how far a certain value is from the mean. As you can see above in the picture, each σ is equally spaced from each other; the distance between 3σ and 2σ is the same as the distance between 2σ and 1σ. More often than not, you will see research articles reporting the SD, rather than the others. This is due to the assumption of the samples having a normal distribution.
6. The 68–95–99.7 rule
This is a rule that has been calculated by mathematicians and used especially in basic probability calculations in statistics. Simply, about 68.27% of the values lie within 1 SD of the mean (μ ± 1σ). Similarly, about 95.45% of the values lie within 2 SDs of the mean (μ ± 2σ). Nearly all (99.73%) of the values lie within 3 SDs of the mean (μ ± 3σ) .
A simple example is the example of IQ scores, of μ = 100, and σ = 15. This means that the values left of the mean are 85(μ-1σ), 70 (μ-2σ), and 55 (μ-3σ); values right of the mean are 115(μ+1σ), 130 (μ+2σ), and 145 (μ+3σ). Approximately 68.27% of people have IQ scores ranging from 85 to 115. 95.45% of people have IQ scores ranging from 70 to 130, and 99.7% of people have scores ranging from 55 to 145.
I have tried to avoid formulas for those with "phobias" of formulas, and explained the above essential statistics information as detailed and simple as possible. If you have any further questions or require more explanations for the above, feel free to ask.
Comments
Post a Comment